Now Reading: Meta’s Llama 4: Ushering in a New Era of Open, Natively Multimodal AI
-
01
Meta’s Llama 4: Ushering in a New Era of Open, Natively Multimodal AI
Meta’s Llama 4: Ushering in a New Era of Open, Natively Multimodal AI

Table of Contents
The landscape of artificial intelligence is constantly evolving, and Meta is once again pushing the boundaries with the introduction of its Llama 4 family of models. Announced as the beginning of a new era in AI innovation, Llama 4 represents a significant leap forward, particularly in the realm of natively multimodal capabilities and open accessibility. This new generation aims to empower developers, researchers, and businesses to build more sophisticated and personalized AI experiences.
Meta emphasizes its continued commitment to open-source principles, making key models within the Llama 4 suite readily available. This release isn’t just about improved performance; it’s about fostering a collaborative ecosystem where innovation can thrive openly.
Meet the Llama 4 Herd: Scout, Maverick, and Behemoth
The Llama 4 collection introduces a tiered approach, offering models suited for different needs and computational resources, all trained with cutting-edge techniques.
Llama 4 Scout: Efficiency Meets Power and Unprecedented Context
- Architecture: 17 billion active parameters, 16 experts (Mixture-of-Experts), 109 billion total parameters.
- Key Features:
- Efficiency: Designed to fit on a single NVIDIA H100 GPU (with Int4 quantization).
- Performance: Outperforms previous Llama generations and competitors like Gemma 3, Gemini 2.0 Flash-Lite, and Mistral 3.1 on various benchmarks.
- Industry-Leading Context: Boasts a massive 10 million token context window, enabling complex tasks over vast amounts of information.
- Multimodal: Natively handles text and images.
- Image Grounding: Best-in-class ability to link text prompts to specific image regions.
- Use Cases: Ideal for applications requiring analysis of long documents (multi-document summarization), extensive user history processing for personalization, reasoning over large codebases, and precise visual question answering.
Llama 4 Maverick: Peak Performance in its Class
- Architecture: 17 billion active parameters, 128 experts (Mixture-of-Experts), 400 billion total parameters.
- Key Features:
- Top-Tier Performance: Beats leading models like GPT-4o and competitors such as
Google's latest Gemini modelson a wide array of benchmarks. Achieves comparable results to DeepSeek v3 on reasoning and coding with significantly fewer active parameters. - Cost-Efficiency: Offers a best-in-class performance-to-cost ratio. An experimental chat version achieved a high ELO score (1417) on LMArena.
- Deployment: Fits on a single NVIDIA H100 host, facilitating easier deployment.
- Multimodal Strength: Excels in precise image understanding and creative text generation.
- Top-Tier Performance: Beats leading models like GPT-4o and competitors such as
- Use Cases: Suited for general assistant and chat applications, sophisticated image analysis tasks, content creation, and demanding reasoning/coding problems where top performance is crucial.
Llama 4 Behemoth: The Powerhouse Teacher (Preview)
- Architecture: 288 billion active parameters, 16 experts (Mixture-of-Experts), nearly 2 trillion total parameters.
- Key Features:
- State-of-the-Art Intelligence: Among the world’s most powerful LLMs, outperforming models like GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro on several STEM benchmarks (e.g., MATH-500, GPQA Diamond).
- Teacher Model: Used via a process called co-distillation to significantly improve the quality of Llama 4 Maverick.
- Multimodal: Like its smaller siblings, incorporates multimodality.
- Status: Currently still in training and not yet released. Meta plans to share more details in the future.
- Role: Serves as the foundation and “teacher” for the Llama 4 family, enabling the smaller models to achieve their impressive capabilities through knowledge distillation.
Architectural Innovations Driving Llama 4
The performance gains and new capabilities of Llama 4 are not accidental. They stem from several key architectural and training advancements:
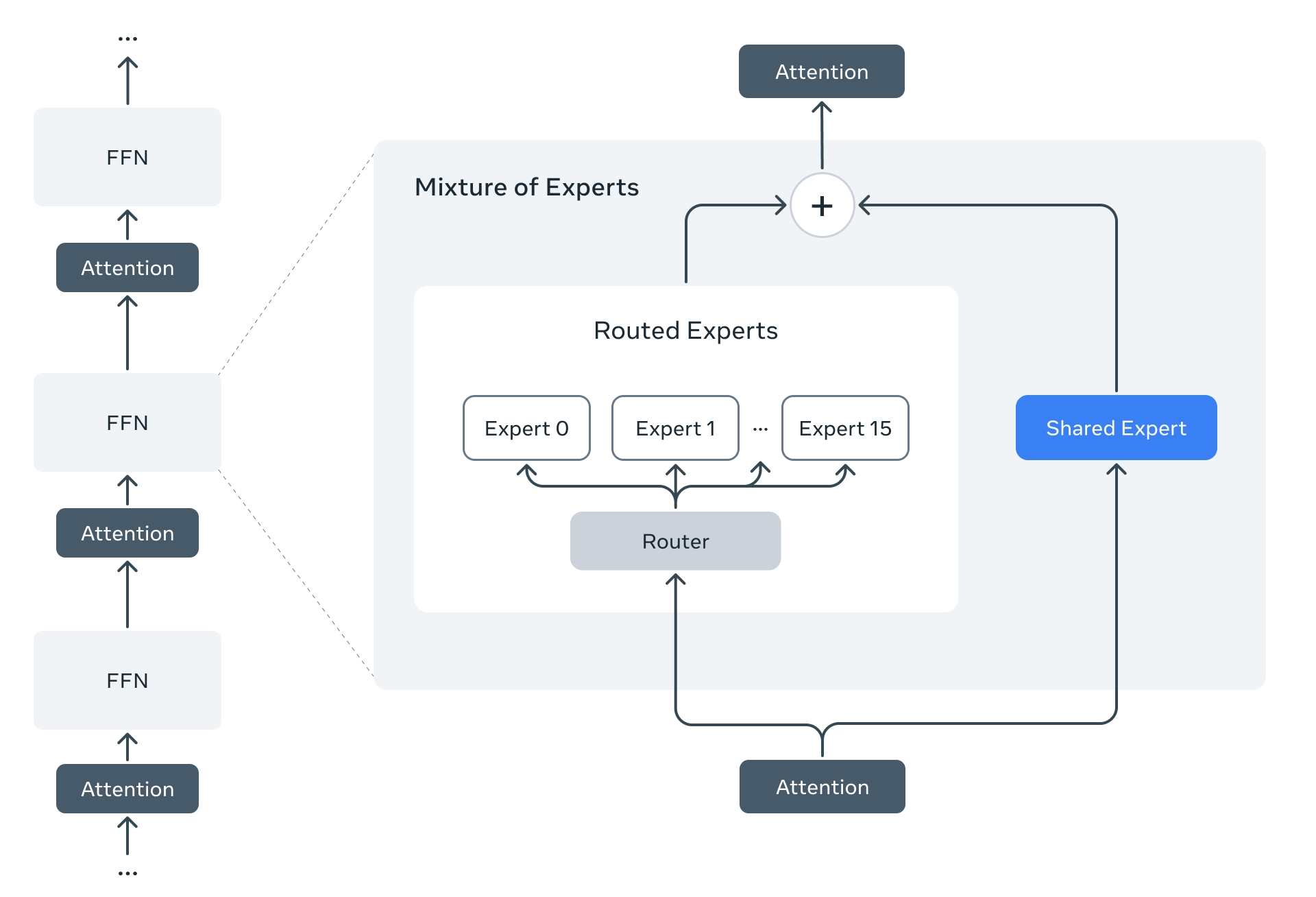
1. Mixture-of-Experts (MoE) Architecture
Llama 4 marks Meta’s first use of MoE in its open models. Instead of activating all model parameters for every calculation, MoE models route tasks (like processing a token) to specialized “expert” sub-networks.
- Efficiency: Only a fraction of the total parameters are active at any given time, making both training and inference more computationally efficient.
- Quality: For a fixed computational budget during training, MoE architectures generally achieve higher quality compared to traditional dense models.
- Implementation: Llama 4 Maverick, for example, has 17B active parameters but 400B total parameters spread across 128 routed experts and a shared expert. This structure enhances inference speed and reduces serving costs.
2. Native Multimodality with Early Fusion
Unlike models where vision capabilities are bolted on later, Llama 4 is designed with native multimodality from the ground up.
- Early Fusion: Text and vision tokens are integrated early in the process into a unified model backbone.
- Joint Pre-training: This approach allows the models to be pre-trained simultaneously on vast datasets containing text, images, and video frames, leading to a deeper, more integrated understanding across modalities.
- Improved Vision Encoder: Based on MetaCLIP but further trained alongside a frozen Llama model to better align visual understanding with the language model’s capabilities. Models were pre-trained on up to 48 images and tested successfully with up to eight simultaneous image inputs.
3. Advanced Training Techniques
- MetaP: A novel technique developed by Meta to reliably set crucial hyperparameters (like learning rates and initialization scales), ensuring stability and transferability across different model sizes and training setups.
- Massive Multilingual Data: Pre-trained on data covering 200 languages (over 100 with >1B tokens each), representing 10x more multilingual tokens than Llama 3, enhancing global applicability.
- FP8 Precision: Training utilized FP8 precision for efficiency without sacrificing quality, achieving high TFLOPs/GPU utilization (e.g., 390 TFLOPs/GPU on 32K GPUs for Behemoth).
- Vast Dataset: The pre-training data mixture exceeded 30 trillion tokens (more than double Llama 3’s), incorporating diverse text, image, and video sources.
- Mid-Training Enhancement: A distinct phase after initial pre-training focused on improving core capabilities, including long context extension using specialized datasets.
4. Unprecedented Context Length (iRoPE Architecture)
Llama 4 Scout pushes the context window to an industry-leading 10 million tokens (up from 128K in Llama 3). This is enabled by:
- Specialized Training: Pre-trained and post-trained with a 256K context length to build strong length generalization.
- iRoPE Architecture: A key innovation using interleaved attention layers without positional embeddings, combined with inference time temperature scaling of attention. The “i” signifies the interleaved layers and the goal of supporting “infinite” context, while “RoPE” refers to the rotary position embeddings used in most layers.
Refining Intelligence: The Llama 4 Post-Training Pipeline
Achieving raw capability is only part of the equation. Post-training fine-tunes the models for safety, helpfulness, and conversational ability. Llama 4 utilizes a revamped pipeline:
- Lightweight Supervised Fine-Tuning (SFT): Initial tuning on high-quality examples. Critically, Meta removed over 50% of data tagged as “easy” (using Llama models as judges) to focus SFT on harder, more informative examples.
- Online Reinforcement Learning (RL): This stage saw significant innovation.
- Hard Prompt Focus: Carefully selected harder prompts led to step-changes in performance, especially in reasoning, coding, and math.
- Continuous Online RL: An iterative process alternating between training the model and using it to filter prompts, retaining only medium-to-hard difficulty ones for further training – improving compute/accuracy trade-offs.
- Lightweight Direct Preference Optimization (DPO): A final tuning step to address specific response quality issues and corner cases, balancing intelligence with conversational nuance.
This pipeline, particularly the data curation and continuous online RL, was crucial for balancing multimodality, reasoning, and conversation while pushing state-of-the-art performance, especially for Llama 4 Maverick. Scaling this process for the 2-trillion parameter Llama 4 Behemoth required significant infrastructure overhaul, including optimized MoE parallelization and a fully asynchronous online RL framework, yielding ~10x training efficiency gains.
Commitment to Openness, Safety, and Responsible AI
Meta reaffirms its dedication to open development while prioritizing safety and mitigating risks.
- Open Access: Llama 4 Scout and Maverick are available for download via llama.com and Hugging Face, with partner platform availability rolling out.
- Integrated Safety: Mitigations are built-in at every stage, from pre-training data filtering to post-training safety tuning.
- Open Source Safeguards: Meta provides tools developers can integrate:
- Llama Guard: Detects harmful inputs/outputs based on defined policies.
- Prompt Guard: Identifies malicious prompts (jailbreaks, injections).
- CyberSecEval: Tools to assess and reduce AI cybersecurity risks.
- Rigorous Testing: Systematic evaluations and adversarial red-teaming are employed. This includes Generative Offensive Agent Testing (GOAT), using AI to simulate adversarial attacks, increasing testing coverage and efficiency.
- Addressing Bias: Recognizing the tendency for LLMs to exhibit biases present in internet training data, Meta actively works to make Llama 4 more neutral and capable of representing multiple viewpoints without judgment. Llama 4 shows significant improvement over Llama 3 in reducing refusals on debated topics and responding with less political lean, comparable to models like Grok, though Meta acknowledges ongoing work is needed.
The Future is Multimodal and Open
The Llama 4 family represents more than just incremental improvements. By combining native multimodality, efficient MoE architectures, massive context windows, and a strong commitment to open access and safety, Meta is providing powerful tools for the next wave of AI innovation.
Whether for developers building cutting-edge applications, enterprises integrating AI into workflows, or researchers exploring the frontiers of intelligence, Llama 4 Scout and Maverick offer compelling options. As Meta continues to develop these models and the surrounding ecosystem, the potential for creating richer, more personalized, and helpful AI experiences grows significantly.
Get started with Llama 4:
- Download Llama 4 Scout and Maverick: llama.com and Hugging Face
- Try Meta AI (powered by Llama 4): Available in WhatsApp, Messenger, Instagram Direct, and on the Meta.AI website.